
ABSTRACT: This paper demonstrates a methodology that incorporates process analysis, failure modes and criticality assessments, natural and man-made hazards and risk management, in order to broaden disaster re-covery plan (DRP), usually connected with IT systems and technologies, to the process chemical industry.
When discussing a chemical plant, the critical infrastructure for continuity of work and production goes beyond computer and data systems. Preparation of a comprehensive DRP for a chemical plant needs the in-sight of engineers and experts from several disciplines: apart from chemical, geotechnical, mechanical and structural engineering issues like the durability of a plant and its utilities, other unique subjects should be con-sidered, such as hazardous materials and waste, emissions treatment, pollution prevention and more; also, the possible causes for a disaster are not only human induced or natural, but can arise from the process itself (e.g. high pressure).
In this study we describe the methodology and its applicability in some case studies belonging to the process industry sector, and argue that it is suitable for other industrial sectors as well.
Keywords: disaster recovery plan (DRP), failure modes, process industry, process hazard analysis (PHA), criticality assessment, risk management.
Alex Cohen – Ceo
Anat Tzur – Engineering VP
Alina Larin – Head of Simulation and Energy department
Adi Malachi – B.Sc. In chemical engineering
1 INTRODUCTION
1.1 Disaster Recovery Plan
Disaster Recovery Plan or DRP is comprehensively implemented in organizations, businesses and companies world-wide. Constituting a major part of business continuity planning, it usually regards IT systems: since major loss of IT data or infrastructure could cause extreme functional difficulties (even up to costing the company its long-term survival), companies and organizations need to ensure the availability of their critical systems, and to be able to recover from disruptions at minimal losses of time and money.
To prepare a DRP, the organization first needs to have some sort of risk assessment, considering all different possible causes leading to unwanted scenaria – natural disasters, infrastructure failure, human errors, etc.; and their possible consequences for processes or units within the organization.
In accordance with these sets of causes and impacts, the recovery plan should deal with four aspects of a possible unwanted event, and suggest measures where relevant:
- The prevention stage – implementing measures to prevent the unwanted event from occurring.
- The detection stage – implementing measures to detect unwanted events as soon as they start.
- The immediate response stage – what should be done upon detection of the unwanted event, with the possibility of mitigating it – controlling its scale and limiting damages.
- The recovery stage – restoring the functionality of the system after the unwanted event and managing business continuity until a certain degree of functionality is achieved.
Obviously, there could be various suggestions for protection; the strategy selected for the recovery plan is usually the cost-effective one: a result of weighing the extent of possible damage against the cost of the suggested measures.
1.2 Why DRP for the process industry is not trivial
First, in a chemical plant the possible causes for a disaster are very diverse, and are not only human induced or natural, but can arise from the processes themselves, e.g. process conditions of high pressure and temperature; use of flammable substances at explosive concentrations; runaway reactions; etc.
Second, the critical infrastructure for continuity of work and production is different than the usual computer and data systems: not only does the plant itself need to withstand the disaster and continue working, there are many other unique issues that should be considered as they could be essential for production. For example: the subject of pollution prevention – will the plant's wastewater treatment facility be functional? If not (or if only partially), are there other solutions to treat or safely and legally dispose of the wastewater? Similarly, attention should be given to hazardous materials and waste, emissions treatment, and more.
And finally, the possible impact of a disaster in a chemical plant could be of significance substantially different than loss of production and financial loss: it could lead to fatal or irreversible injuries, or adverse environmental impact, or exposure of employees and owners to criminal suits.
As a result, the risk analysis needed to properly identify all failure modes should be very detailed, extensive, and requires the insight of engineers and experts from several disciplines: chemical, geotechnical, mechanical and structural engineering, environmental specialists, environmental lawyers, process safety experts and so on. Building the recovery plan is equally multidisciplinary and complex.
In this paper we suggest a methodology to broaden DRP to the process industry, applying analysis tools and methods that are usually used in that sector, incorporating the results into a procedure for recovering from malfunction.
2 methodology for DRP in the process industry
2.1 Getting started
As stated before, a chemical plant can be very complex, involving more than one production process; and while production processes by themselves can be more or less intricate, one should bear in mind that the entire scope of a chemical production process usually also includes utilities such as process water, cooling water, process air, instrument air, steam, wastegas and wastewater treatment and so on. Those utilities are very often on the site level, servicing several plants or facilities. So preparing a DRP for a company as a whole can be extremely complicated and even unpractical. Thought should be given to the scope of work definition, breaking down the complete plant into more reasonable segments. The segments can be vertical-sectional like different production processes, and/or cross-sectional like utilities.
2.2 Process industry requires process hazard analysis
Once the scope of the process is well and suitably defined, an assessment is performed in order to have a thorough understanding of all possible failure modes in the process. More specifically, a process hazard analysis or PHA is carried out – a systematic assessment of the potential hazards associated with the process itself. There are many methodologies for conducting a PHA, e.g. what-if, checklist, Failure Mode and Effects Analysis (FMEA), Event Tree Analysis (ETA), Layers of Protection Analysis (LoPA) and others. We believe the most suitable method in this case is Hazard And Operability (HAZOP) study, but in some cases other methods are more appropriate as will be shown in the case studies.
A HAZOP study is a brain-storming technique involving experts who have knowledge on the process from various aspects – process engineers, control engineers, safety and environment experts, electricians, process operators, maintenance personnel etc. The study is facilitated by an experienced leader, systematically applying sets of keywords to "generate" deviations from the intent and design of the process; for example: "more pressure", "less temperature", "reverse flow". For each feasible deviation, the team of experts finds possible causes and impacts; and also discusses all the control, prevention and detection measures that are installed and used, that could prevent the deviation and its consequences. Two things should be especially remembered for the purpose of DRP: 1) all relevant utilities should be discussed together with the process; 2) all possible impacts should be considered: failures that risk personal safety of employees and/or people outside the plant, financial loss, adverse environmental impact, damage to business continuity, exposure of employees and owners to criminal suits, etc.
The ultimate result of a HAZOP study is usually the decision, whether the existing safety measures are adequate or more measures should be considered. However, for the specific purpose of preparing a DRP this could be less important – the main intent is to identify failure modes.
The PHA deals with failure modes due to process deviations and human errors. In order to assess the durability of the process (with its utilities) in external events which do not arise from the process itself, more experts should be consulted: the issue of natural disasters such as earthquakes or floods is treated by geotechnical, mechanical and structural engineers; the subject of surrounding fire and explosion hazards (a serious issue when dealing with the chemical process industry which often involves the wide use of flammable and reactive substances), is dealt with experts in this field.
2.3 Criticality assessment
Now that we have identified all the possible failure modes and their corresponding impact, the company should make a decision on what it considers a critical failure – a failure that needs to be prevented with a high degree of certainty. In this sense, critical failures could be of a wide range and could be defined as failures that cause fatal or irreversible injuries, or significant direct financial loss, or adverse environmental impact, or irreversible damage to business continuity, or exposure of employees and owners to criminal suits.
Failure modes which are considered critical should be put on top priority for further assessment and prevention. Dealing with other failures could be postponed to a later time, depending on company's policy.
2.4 Frequency of critical failures
Natural disasters and fires rarely have frequencies. However, in the process industry we are also dealing with process deviations and human errors – which have well established and documented databases of frequencies and statistics. So, at least for the failure modes resulting from the process itself, expected frequencies can be assessed and calculated. This will give better decision tools in the next step – preparing the actual recovery plan.
In order to assess failure modes' frequencies, another method of PHA may be needed – Fault Tree Analysis (FTA): a deductive analysis in which an undesired top event or state of a system is analyzed backwards, using boolean logic to combine a series of lower-level events. Another possible method can be Event Tree Analysis (ETA): an inductive analysis in which the possible (forward) outcomes following an initiating event are analyzed, using binary logic as an event either has or has not happened or a component has or has not failed. Usually ETA is more suitable for relatively simple processes or failure scenaria, where the complexity and number of possible causes is low and the binary structure is applicable.
2.5 Recovery plan
The actual recovery plan should, as all DRPs should, deal with the prevention stage, the detection stage, the immediate response stage and the recovery stage. Because we are dealing with the heavy, process industry and often with the chemical industry, it could be advisable to involve emergency preparedness and response experts at this stage, to give their knowledge and input on subjects such as treatment of chemical releases, personnel evacuation, reporting to the authorities and collaborating with them and so on.
The decision on what measures should be taken at the different stages can be greatly assisted by the critical failures' assessed frequency: a typical plant's lifetime is a few decades; if the expected frequency of a failure is lower, there is little justification to heavily invest in protective measures for this specific failure. However, if the expected frequency is high, obviously the company should prevent such a failure and be prepared to deal with it.
3 case studies
3.1 Case study no. 1 – emission treatment
In this case, the process to be analyzed had been pre-determined as critical by the company. It was the end-device used to treat and reduce emissions to air in one of their production sites – specifically a thermal oxidizer. The oxidizer is connected to several production processes and is used to reduce emissions, and convert hazardous and environmentally problematic substances into chemicals that are suitable for emission into the atmosphere. It actually does so by burning the streams of wastegas in a controlled manner under high temperature conditions. Afterwards the oxidized wastegas goes through a steam-production unit where it cools down (and is used to produce steam at the same time); then it passes through several devices used to remove harmful particulates and substances that should not be released to the air (absorption columns and de-NOx); and the "clean" wastegas is finally released to the air via a stack.
Since it plays such a significant role in emission control, the oxidizer system's criticality is three-fold: 1) its failure might cause adverse environmental effects; 2) the authorities in Israel forbade the company from working without it for more than two weeks a year – thus putting owners and managers under potential threat of law-suits in case of violation; 3) production and business continuity can be seriously damaged if the oxidizer doesn't function for more than two weeks. As a result, the company wanted to prepare a DRP concerning the oxidizer: what are the possible failure modes that could stop its functionality for a significant period of time, and how should the company prepare itself for such an unwanted event.
The thermal oxidizer was equipped with many safety control functions, intended to keep the operational parameters within the required boundaries and prevent deviations from developing into harmful scenaria. For example: the water in the steam boiler needs to be maintained at a high enough level, otherwise the gases entering the boiler are not cooled enough and the boiler might be damaged due to the high temperature – therefore there is a cascade of switches, each of them is supposed to trip (stop) the oxidizer's burner when the boiler's water level gets increasingly low as a result of a variety of possible reasons (e.g. water feed pump failure). In order to thoroughly comprehend the possible failure modes of the system, a HAZOP study was conducted, enabling us to identify all the process-related scenaria leading to possible failure of the oxidizer. To determine whether each failure mechanism is critical – i.e. shuts the oxidizer down for more than two weeks – we consulted with managers of the oxidizer's facility and the plants using it, maintenance manager, control and instrumentation manager and utilities manager. They could supply information on the extent of damage, dead time expected, spare parts inventory, etc.
At this stage, we were faced with twelve process-originated failure mechanisms, each leading to a critical failure of the oxidizer. We could identify the number of protection layers, intended to prevent each deviation from deteriorating to critical failure. It was interesting to note that in some cases, what the plant thought were several independent protection layers actually had a common mode that annulled the redundancy and sometimes turned them into a single protection layer. To assess the failure modes frequency we used the FTA method. The results can be seen in table 1.
Table 1. Some of the failure modes in case study 1 and their calculated frequencies.
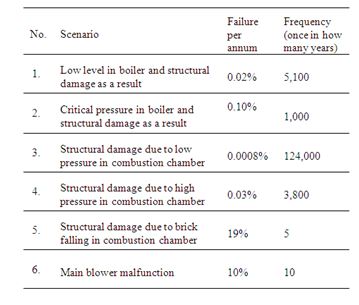
As can be seen from the table, the results clearly divide in two: 1) process deviations that resulted in critical failure due to malfunction of all of the protection layers – these had low frequencies of once in thousands of years; and 2) local, specific malfunctions (such as a brick falling or main blower breaking down) that have no response in the control system and immediately deteriorate to critical failure – these had considerably higher frequencies.
The ultimate goal of the work was of course preparing the DRP. Here the input from the previous stages was incorporated into the DRP:
1) During a typical lifetime of a chemical plant, critical failures due to process deviations and malfunction of all the protection layers are not expected. This means there is no need for the DRP to focus on the prevention and detection of such malfunctions (so there is no major necessity to add more control measures).
2) The main issues are natural disasters and the local, specific malfunctions that have no response in the control system. These are hard to predict and/or prevent, and as a result the DRP should put more emphasize on the immediate response and recovery stages: how to handle production when there is a critical failure of the oxidizer (some facilities will have to shut down immediately, others will be able to continue production but will have to transform their emission treatment method); what spare parts should be kept in stock available within few days (instead of being shipped from abroad); etc. Experts and specialists from fields like emergency preparedness and EHS gave their advice here on subjects such as what the plant and company should do when they need to work without the oxidizer (for less than two weeks) and have to treat their emissions in an alternative way, how to build a procedure for reporting and operating following a critical failure and also how to guide and practice relevant personnel accordingly – such a procedure greatly resembles emergency response procedures and can be based on the same organizational structures and chain of report.
3) Since the total expected frequency of critical failure is low, the company decided that it is not justified to keep extremely long-term stocks of products in order to maintain business continuity. Only medium-term stocks are required.
3.2 Case study no. 2 – drug stability
The analysis was performed for a pharmaceutical company, and the analyzed process was the storage of drugs and medicines in stability rooms. The purpose of stability rooms is to manufacture constant temperature and humidity conditions, the equivalents of possible storage conditions at the consumer's. Samples from each batch are kept in the stability rooms, enabling the plant to monitor the stability of the drugs and assess their expiration date. To supply the required conditions, the stability rooms are equipped with air treatment units, humidifiers, ventilation systems and chillers.
This process was not suitable for HAZOP analysis as it was not a complicated process with many controls, and it relied mainly on systems that were regarded as "black boxes" and were assumed either to work or not but were not further investigated (it could even be argued that it wasn't a process per-se). Therefore, a risk matrix/what-if evaluation was performed to define potential causes for disruption to the conditions in the different rooms and evaluate their impact. Among the analyzed causes: electricity failure, fire, extreme weather conditions, supporting system failure, etc. The evaluation was done by ranking the potential causes' gross likelihood and severity of consequences (both scales can be determined according to the company's decision or policy); the potential risk being the multiplication of likelihood and severity. It should be noted that the likelihood in this stage had only been roughly estimated and an exact calculation was done at a later stage, only for the critical failures – see below The potential risk was divided into three categories – low, medium and high.
The risk matrix is demonstrated in figure 1.
The company defined what would be a critical failure – disruption that would last for more than a given number of hours without the samples being transferred to a functioning room with the required conditions. This would result in such damage to the samples that the entire batches will be disqualified. Such a failure corresponded to the highest potential risk in the risk matrix. Thus we were able to identify four main critical failures, their criticality being mainly financial (loss due to batches being disqualified) but also relating to the company's reputation.
To get these critical failures' frequencies, we used ETA analysis.
Now the company needed recommendations for its DRP regarding prevention, detection and immediate response (the recovery stage was not dealt with in this scope of work). The recommendations encompassed several aspects:
- The company's requirement was that the stability rooms' reliability will be at least equivalent to SIL2 (SIL or Safety Integrity Level as defined by IEC 61511 and IEC 61508, gives a numerical value between 1 and 4 to the reliability of safety instrumented functions). The frequencies calculated for the critical failures were compared to SIL2 frequency (0.00876 fpa), and where the frequencies were higher than required, prevention measures were added to reduce the frequency to the wanted level.
- We identified that in general there were five layers of protection in the stability rooms; however, in some of the critical failure mechanisms not all of the protection layers existed – so recommendations were given to add protection layers.
- The immediate response once all the protection layers have failed is to evacuate the samples to other rooms that have exactly the same conditions. Naturally the best thing would be to have a redundancy of specific stability rooms operating in the same site, so that the samples could be quickly transferred. This will also allow for more time to try to overcome the disruption before transfer becomes a must. However, not all the stability rooms had such
backups and a plan had to be prepared to evacuate samples from some of the rooms to suitable rooms at a different site, taking into account the transport time when deciding when evacuation is needed. Alternatives on the same site were also proposed, that could
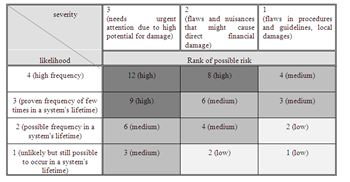
Figure 1. Example of risk matrix used for primary evaluation of failures.
be operated within a reasonable time framework, but it couldn't be guaranteed that in those alternatives there will always be enough room for the samples.
4 CONCLUSIONS
In this article we have demonstrated the applicability of a comprehensive methodology used mainly to backup IT systems for recovering from a critical problem in the process industry.
Thorough understanding of all failure modes in a chemical industrial process requires analysis of various failure modes involved with human errors, process deviations, natural disasters, and any combi-nation whereof. The consequences of each failure are used to quantify criticality. Where, in this sense, critical failures could be defined as failures that cause fatal or irreversible injuries, or significant direct financial loss, or adverse environmental impact, or irreversible damage to business continuity, or ex-posure of employees and owners to criminal suits. Further analysis of existing and suggested protection systems followed by procedure for recovering from malfunctions can be implemented to minimize losses and enable continuity.
Although the case studies shown are related to the process industry, it is clear that it could be imple-mented for any other complex system as long as the failures modes and respective consequences could be analyzed and quantified.
REFERENCES
Lees, Frank P., 1992, Loss Prevention in the Process Industries, (2nd edition), Butterworth-Heinemann.
Kletz, Trevor, 1992, HAZOP AND HAZAN – Identifying and Assessing Process Industry Hazards, (3nd edition), Institution of Chemical Engineers.
VROM, Publication Series on Dangerous Substances 4 (PGS 4), (2005) Methods for determining and processing probabilities.
Wells, Geoff, 1996, HAZARD IDENTIFICATION AND RISK ASSESSMENT, Institution of Chemical Engineers.








{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}